Naming files and managing versions: good habits
Contents
Recommendations exist for naming files for efficient classification. Using standardized, consistent names with differentiating elements (such as the production date) in a set of files or documents makes it easier to identify the content of a file or document before opening it. It can be useful,for example, to include important metadata in file naming rules (e.g. [Date]_[Run]_[SampleType].)
These rules can be formalized in a naming convention, like those applied by NASA or the American organization ARM for climate change studies.
The convention, which clarifies descriptive information about the content (date, place, version, author, etc.) can be indicated in a readme file in the margin of the data set.
Naming your files properly
Several universities and organizations list best practices for naming files (see resources below).
It may be recommended:
- Avoid excessively long names (maximum 25 characters).
- Avoid non-alphanumeric characters in file names and separate naming elements with underscores rather than spaces as operating systems interpret them differently.
- Standardized dates: the recommended format of the international standard ISO 8601 is: YYYY-MM-DD (year-month-day).
When defining naming rules, it may be relevant to take into account the project acronym, the different types of data (e.g. field observations in the form of a table, simulations, protocols, etc.), file formats (.csv, .jpeg, .fid etc.), unique characteristics of data files (e.g. creation date, project name, experimental conditions), standard abbreviations for some of these characteristics, researcher initials and the file version. For example:
- Name and acronym of the project or experiment
- Location/ spatial coordinates
- Name/initials of the researcher
- Date or range of dates of the experiment
- Type of data
- Conditions
- File version number
Ex: MMDDYYYYTHH:MM_ProjIDXX_expXX_v01.csv
Date_Project identifier_experiment identifier_version
At the beginning of a research project, it is also important to plan a tree structure of folders or files to be able to find the elements you need quickly and easily. This is even more important when several people or a team work together on the same research or when people work in succession.
It is generally advised to limit the number of levels in a folder to three or four, with a maximum of ten elements in each list.
It can be useful to regularly distinguish work in progress from finished work when organizing folders. Throughout the project, check whether documents in folders or files can be deleted or should be kept. File naming conventions should be documented and shared (e.g. via a readme file).
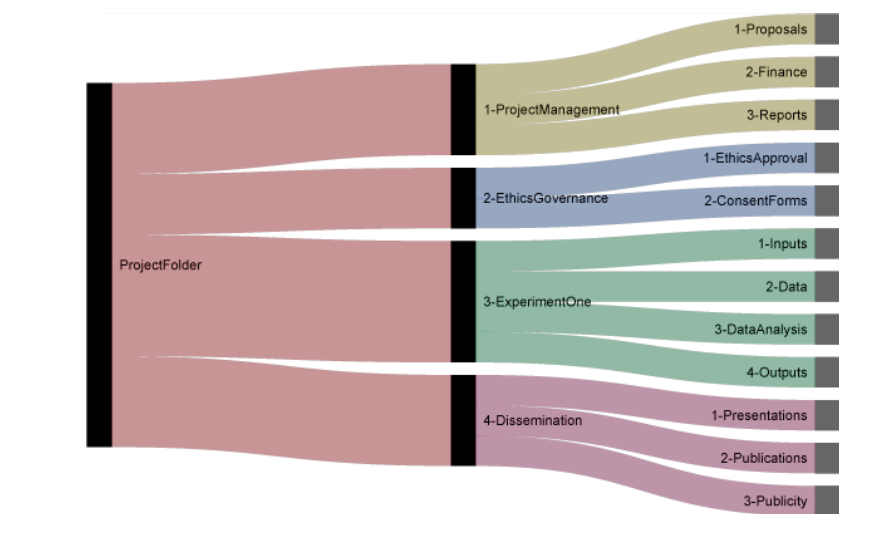
Lastly, Nikola Vukovic, researcher in neuroscience at UC San Francisco, proposes an organization by project, distinguishing the management of projects with administrative and financial elements, the ethical aspect, experiments with different data states and finally, publications. This type of organization can be adapted to many disciplines.
- Some general resources: :
o INRAE summarizes the main recommandations.
o MIT provides a worksheet with relevant file naming practices and several other tools.
o University of Edinburgh and the Digital Curation Center specify a set of 13 rules for naming files efficiently, particularly for archiving e-mails and attached documents.
o Stanford University presents several examples: data collected by a PhD student and best practices.
o Cambridge University offers an 8 minute video dedicated to “File naming” particularly adapted to developers with a very complete example of the convention developed by the University of Queensland.
o The platform DataOne gives best practices best practices et and some other tools for file naming.
Certain branches of chemistry, like computational or physical chemistry, require the creation and production of computer programs in order to perform specific calculations. When managing files and scripts daily, the management of versions must not be neglected.
It may be necessary to go back to an earlier version of the script if the analyses prove to be incorrect, or if you wish to redirect the project.
Software dedicated to versioning can be used to track the history and all the modifications made to a file. This is the case for Git, an open source software widely used by researchers. It can be used with local files or in a network, but it is not simple. To appreciate all the tool’s features, use the terminal and command lines.
There are, however, a certain number of user graphs to avoid command lines. Find a list of the interfaces here (most are free-of-charge). Note that the interfaces only cover some of Git’s features. Choose the graphic interface best suited to your needs. Some solutions, however, are particularly popular, such as the free interface: Git for Windows. GitHub also offers a downloadable interface for Windows desktop here.
For more information on Git, see the official documentation available here as well as this guide in French, which may help to understand how the software works.
In an article published on June 26, entitled “The 6 Git Commands Data Scientist Should Know”, the blog Towards data science summarizes the 6 verbs used to manage a project and to create a folder on GitHub.
Finally, think carefully about how to store directories. Your department’s or institution’s server is a first point of entry. But if you wish to share your project more openly, you can use a host such as GitHub or GitLab. These two tools, based on Git, allow you to contribute efficiently to a work space and to collaborate easily. GitLab is open source. GitHub is currently the most used, but it is proprietary. Computational chemistry projects like OpenChem developed by the University of North Carolina can be found there.
To go deeper, see the Australian National Data Service (ANDS) and the section “working with data” for a full update about managing data versions with examples, scenarios and tools.